En la actualidad, existen más de 300 motores de bases de datos en el mercado. A pesar de ello, pocas bases de datos han sido desarrolladas específicamente para Machine Learning (ML). Existe un producto llamado MLDB que es una base de datos de código abierto para ML. Sin embargo, la empresa detrás de MLDB fue adquirida por Element AI. Kinetica es otra startup que ha desarrollado un producto para el análisis de datos de Machine Learning que distribuye la carga de trabajo computacional entre GPU y CPU de manera simultánea.
La base de datos Kineteca funciona directamente en la memoria, al igual que Apache Spark. Las bases de datos en memoria (in-memory) son considerablemente más rápidas que aquellas que funcionan exclusivamente en disco duro. Kinetica se refiere a su base de datos como una “base de datos vectorizada, columnar y memory-first diseñada para cargas de trabajo analíticas (OLAP)” que “distribuye automáticamente cualquier carga de trabajo entre CPU y GPU para obtener resultados óptimos”.
Por lo tanto, Kinetica es capaz de distribuir las cargas de trabajo de Inteligencia Artificial entre CPU y GPU, lo que reduce el costo general del sistema, ya que las tarjetas de GPU son caras. La arquitectura de Kinetica se ilustra a continuación.
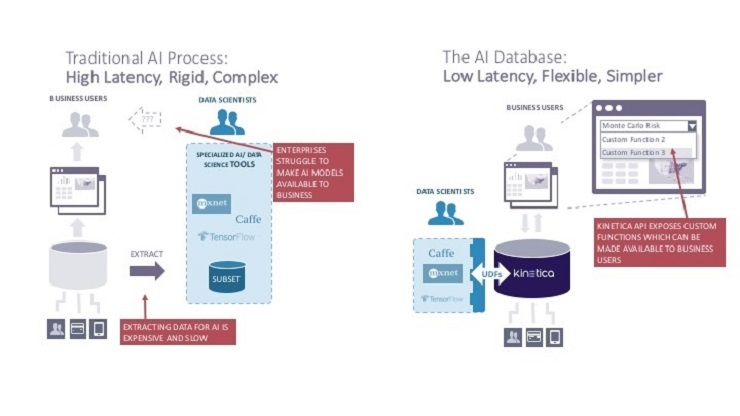
En un white paper, Kinetica explica uno de los beneficios de la arquitectura de su sistema: coloca procesos computacionalmente pesados en los GPU y los procesos menos intensivos en recursos en los CPU. Además, aprovecha la memoria RAM de la tarjeta madre y la memoria de las tarjetas GPU para optimizar el rendimiento.
Al implementar un enfoque basado en columnas, Kinetica es capaz de utilizar el almacenamiento de manera más eficiente, esto en un entorno de análisis de datos y, también, de proporcionar resultados rápidos a consultas. Por el lado negativo, una base de datos de GPU no es óptima para el entrenamiento de modelos de ML. Para este caso, Apache Spark es el mejor producto.
Dos características importantes
• Distribuye la carga de procesamiento entre GPU y CPU
• La memoria GPU y la memoria RAM del sistema se utilizan para procesar y almacenar datos para tareas de IA
El Modelo de Consumo
Sriram Subramanian, director de investigación de IDC, publicó un artículo sobre AI Stacks (Pilas de Inteligencia Artificial) modernas que describe los diferentes modelos de consumo. Aunque no se explica una base de datos para Machine Learning, se ilustran diferentes capas de las pilas de IA, que incluyen el cómputo y la data.
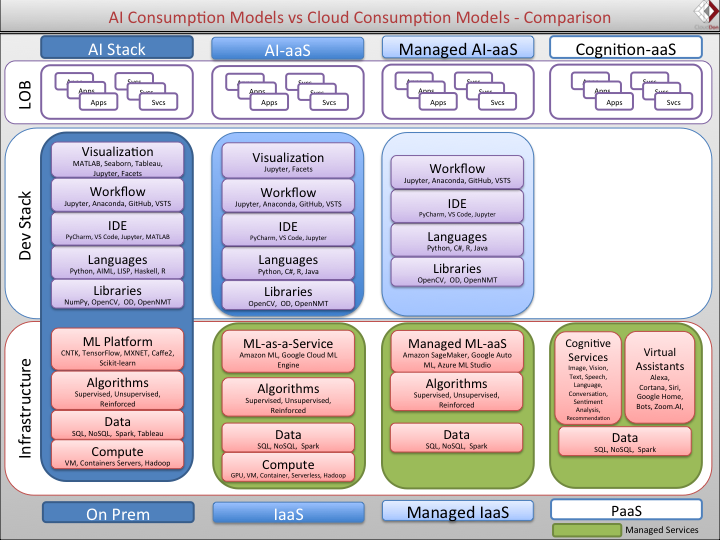
Sriram descompone los modelos de consumo en cuatro tipos diferentes. En la columna on-premise, la capa de cómputo está en la parte inferior de la pila y la capa de datos está justo encima de ella. Sin embargo, para el entrenamiento de ML, el cómputo se lleva a cabo en los GPU y CPU. El tipo de servidor sería el tipo de sistema que se utiliza para ML, ¿como un servidor dedicado, un contenedor, una VM o un servidor compartido, tal vez?
Preguntas Importantes
• Se requiere una base de datos para el entrenamiento de ML?
• ¿Puede un sistema de archivos como Hadoop ocupar el lugar de una base de datos que se usa estrictamente para el entrenamiento de modelos y la inferencia (después de completar el entrenamiento)?
APACHE KAFKA
Apache Kafka es un popular motor de procesamiento de streams, diseñado para funcionar como un sistema altamente escalable que puede procesar un gran volumen de fuentes de datos en tiempo real. Las partes de Kafka incluye a los 1) productores 2) el clúster y 3) los consumidores. Las tres partes permiten a las empresas ingerir datos, procesarlos y generar un resultado de manera organizada. LinkedIn desarrolló originalmente Kafka, luego lo donó a la Fundación Apache. Los desarrolladores de Kafka dejaron LinkedIn y crearon una empresa llamada Confluent, que se centra en Kafka.
Kai Waehner, predicador de Confluent, creó una arquitectura de referencia y un ciclo de vida de desarrollo de ML que se ilustra a continuación. En el lado izquierdo están los sistemas que proporcionan datos a Kafka y Hadoop. Kafka ingiere datos en tiempo real y Hadoop la parte de datos en lote (batch data). TensorFlow y H20.ai se encuentran justo al lado de Hadoop. Hadoop no es una base de datos, sino un sistema de archivos distribuidos que funciona de manera eficiente en grandes grupos de servidores. Sin embargo, el artículo y la arquitectura no proporcionan suficiente profundidad para formar cualquier tipo de opinión o conclusión.
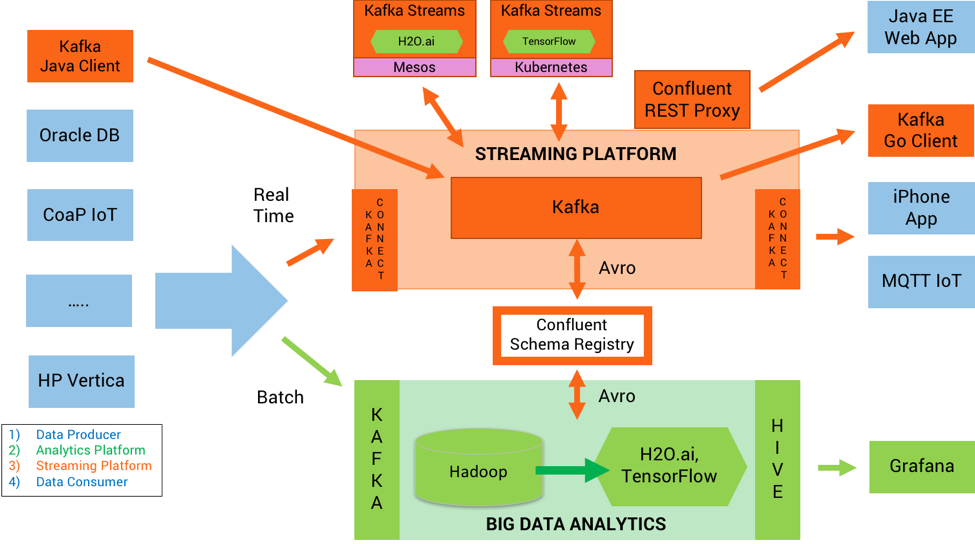
En resumen, se necesitan más bases de datos desarrolladas para Machine Learning.