Probablemente has notado que una búsqueda típica en Google, Bing o Yahoo tarda menos de un segundo en mostrar resultados en tu pantalla. Pero para lograrlo, el motor de búsqueda de tu navegador web necesita estar previamente informado tanto de contenido nuevo como antiguo para que esté disponible cuando sea requerido. Los desarrolladores web diseñan motores de búsqueda basados en componentes dedicados al rastreo web, a la indexación, clasificación y solución de solicitudes web, con el objetivo de brindar respuestas rápidas.
Los motores de búsqueda usan estos componentes (algoritmos) para buscar, clasificar, y brindar las “mejores” páginas web, documentos, imágenes y otros tipos de contenido, facilitando a los usuarios el proceso de búsqueda entre una gran cantidad de recursos disponibles en Internet. Además, estos motores deben ser capaces de proporcionar resultados categorizados con contenido relevante.
Sin embargo, estos motores no están construidos exclusivamente para grandes y conocidos buscadores web. Empresas de todo el mundo e incluso profesionales de diferentes sectores pueden crear sus propios motores para diferentes aplicaciones, como la recuperación de datos de artículos científicos, ofertas de trabajo o precios de productos de moda de cientos de sitios web.
A continuación, te presentamos más información referente a los componentes de un motor de búsqueda, así como una herramienta de open-source para realizar web scraping.
¿Rastreo o extracción de datos de sitios web?
Aunque estas dos definiciones usan algoritmos muy similares, el rastreo (web crawling) y la extracción de datos (web scraping) son dos técnicas diferentes empleadas para recopilar datos de Internet.
Rastreador web (Web Crawler)
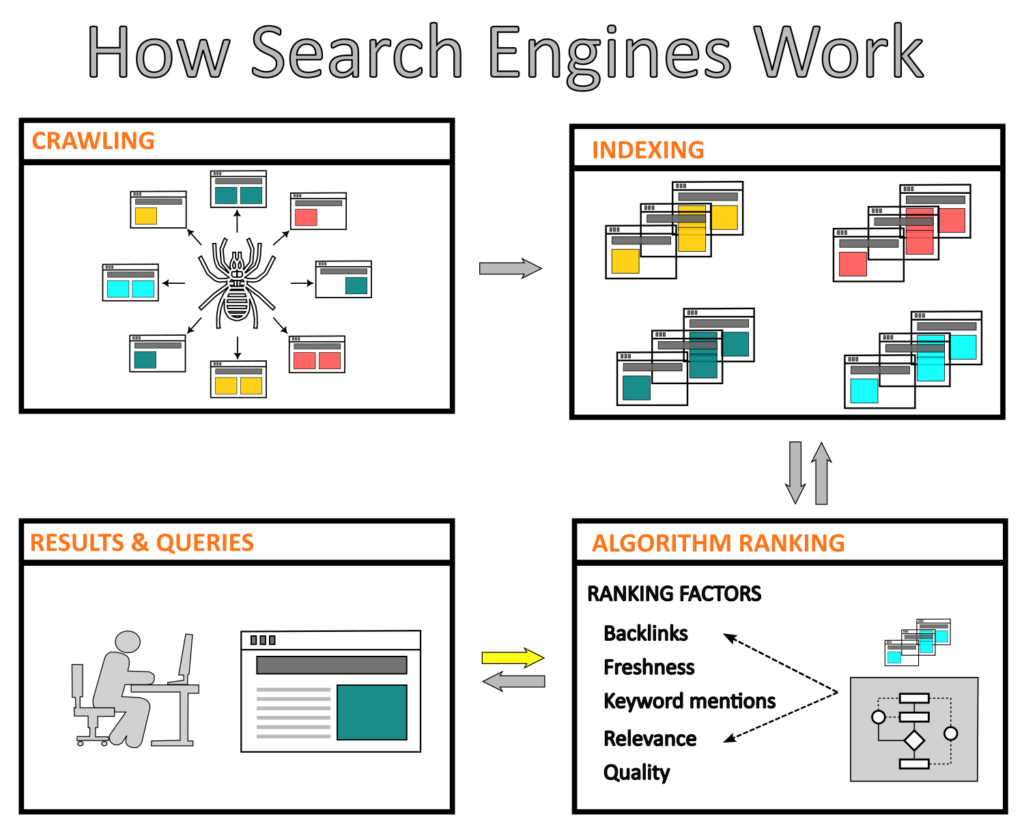
Un rastreador web es un algoritmo, también llamado robot o araña (por su traducción en inglés “spider”), que rastrea todo el Internet mediante una inspección metódica y automática. El rastreador web analiza varias páginas web para recopilar información y crear entradas que serán usadas para indexar dichas páginas posteriormente.
El proceso de crawling comienza con una lista de URL que deben ser visitadas. Luego el rastreador descarga y analiza el contenido para extraer información (por ejemplo, enlaces, archivos de HTML, CSS o JavaScript.) en forma de ítems. Finalmente, el rastreador procesa estos elementos empleando tareas de limpieza, validación y persistencia.
Dado que cientos de páginas web son creadas cada día, el rastreador web debe realizar este proceso una y otra vez, añadiendo nuevas y actualizadas páginas web a su lista de URL.
En términos generales, el rastreo web es un proceso esencial de un motor de búsqueda en el que algoritmos buscan y descargan contenido específico del internet de forma sistemática. Este contenido es usado únicamente para indexar y clasificar páginas web.
Extracción de datos de sitios web (Web Scraping)
El web scraping es el proceso de descarga de datos de páginas web, es decir, los usuarios pueden trabajar con cualquier sitio web a través de la identificación y extracción de objetos. Esta técnica puede ser usada para una amplia gama de aplicaciones, tales como:
Investigación: buscar y descargar información es el primer paso para cualquier investigador en un proyecto en curso, ya sea para fines académicos, de marketing, financieros u otros objetivos empresariales.
Comercio electrónico: en la actualidad, las empresas aplican regularmente mercadotecnia para mantener su competitividad. Por ejemplo, estas deben estar conscientes de precios, ofertas especiales y otros factores externos para estar un paso adelante de sus competidores.
Seguridad cibernética: la creación de contenido se está convirtiendo cada vez más en una parte integral de las empresas. Aunque gran parte de este contenido es público, como los precios de los productos en Amazon o los datos de investigación en una publicación, los datos personales y la propiedad intelectual están expuestos a ataques cibernéticos por parte de actores que desean beneficiarse ilegalmente de ellos. La recopilación de datos permite a los creadores de contenido monitorear y proteger sus datos confidenciales.
En general, el web scraping ayuda a los usuarios a extraer de manera sistemática y automática datos específicos de un sitio web y ponerlos a disposición para diferentes propósitos.
Motor de indexación
La indexación del contenido de los sitios web implica la recolección, la categorización y el almacenamiento de información de las páginas web, para crear una base de datos de fácil búsqueda. Al indexar el contenido, los motores de búsqueda pueden recuperar y proporcionar rápidamente los resultados de la consulta de un usuario.
A continuación una explicación clara y concisa:
“Una vez que tenemos información de las páginas web(…), es necesario entenderlas. Para ello debemos averiguar de qué se trata el contenido y su finalidad. En esencia, esa es la segunda etapa, que se la conoce como indexación”. – Martin Splitt, WebMaster Analista de Tendencias de Google.
Clasificación del motor de búsqueda
Cuando un motor de búsqueda recibe una solicitud de un usuario, debe ser capaz de mostrar resultados que cumplan con ciertos criterios de evaluación. Esto se realiza mediante un algoritmo complejo que utiliza el motor de búsqueda para comparar palabras clave y frases entre la solicitud y el contenido indexado, para luego categorizar los resultados de acuerdo con factores de clasificación.
Por ejemplo, los factores clasificación de Googlebot, sin una orden en particular, son relevancia, calidad, facilidad de uso, ubicación y otros más.
Mejorar la clasificación de sitios web con estrategias de SEO
Cuando los motores de búsqueda no pueden rastrear una nueva página web, se produce un impedimento para que la página se indexe y se muestre en los resultados de búsqueda. Esto puede deberse a varios factores, como errores en el archivo “robots.txt”, problemas de conectividad del servidor, problemas con el diseño del sitio web o problemas con el contenido. Aunque las páginas nuevas pueden tardar algún tiempo en ser rastreadas e indexadas por los motores de búsqueda, si se optimizan correctamente y se solucionan los problemas técnicos, se puede mejorar su visibilidad y posicionamiento en los resultados de búsqueda.
Por este motivo, profesionales previamente formados utilizan técnicas de SEO (Search Engine Optimization, optimización en motores de búsqueda) para mejorar el contenido de acuerdo con determinadas estrategias de optimización, lo que facilita su indexación y su posición en los resultados de búsqueda.
Si deseas mejorar la posición de tu contenido, sigue los siguientes consejos:
- Usa URL cortas.
- Agrega contenido nuevo.
- Crea un título con un número reducido de caracteres.
- Inserta una imagen relacionada con el tema.
- Crea párrafos con no más de 300 palabras.
- Si estás escribiendo una publicación, menciona de 1 a 3 personas como mínimo.
- Define una palabra clave, utilízala en el título y mantén su densidad a lo largo del texto.
Biblioteca de Python para la extracción de dato de sitios web
El web scraping está ganando popularidad en la extracción de datos de sitios web para su posterior análisis. Para realizar web scraping, es necesario tener un conocimiento básico de HTML y CSS, ya que te permitirá entender la estructura de una página web. Además, debes saber cómo usar una herramienta como BeautifulSoup o Scrapy para crear tu algoritmo y extraer datos de forma automática.
Nota: es importante tener en cuenta que la extracción de datos debe ser legal y ética, ya que de lo contrario puede haber sanciones. Para obtener más información te recomendamos revisar la ley DMCA (Digital Millennium Copyright Act, ley de derechos de autor de la era digital).
Scrapy es una biblioteca de rastreo web, de código abierto, basada en Python que permite a los usuarios extraer datos de sitios web. Si bien se creó inicialmente para fines de web scraping, también se utiliza como un rastreador web de uso general. Scrapy se basa en “spiders” (un componente del rastreador), que son un tipo de función, también llamada clases, que definen la técnica para extraer datos de un sitio web en particular. Actualmente, la empresa especializada en rastreo web, Zyte, brinda soporte a esta herramienta.
“Es muy agradable trabajar con Scrapy. Este elimina la mayor parte de la complejidad de las tareas de rastreo web, permitiendo concentrarte en el trabajo principal de extracción de datos”. –Jacob Perkins, autor del libro Python 3 Text Processing with NLTK 3 Cookbook.
Para usar Scrappy, debes instalar una IDE de Python en tu máquina y ejecutar en el command prompt o terminal el siguiente comando “pip install scrapy”. Si usas una distribución de Anaconda, utiliza “conda install -c conda-forge scrapy”.