¿Cómo PrestoDB y Trino pueden ayudarte a gestionar bases de datos SQL distribuídas? Primero, es importante recordar que una base de datos SQL distribuida está formada por múltiples bases de datos, cada una de las cuales contiene un subconjunto de los datos, que funcionan juntas como una sola. De esta manera, se agrega rendimiento o capacidad de almacenamiento al sumar más instancias de base de datos. El motor de software usado tiene la tarea de garantizar la consistencia de los datos. Además, los otros softwares se comunicarán con él, en lugar de cada una de las instancias de base de datos separadas.
En este artículo, vamos a explicar más sobre los orígenes de PrestoDB y Trino, cómo funcionan y sus principales características.
Origen y principales características de PrestoDB
Facebook desarrolló PrestoDB en 2013 como una solución para consultar su gigantesca base de datos. La tecnología existente en ese momento no estaba lista para consultar cantidades tan grandes de datos ni para consultar varias fuentes de datos al mismo tiempo. Estos eran los desafíos que debían resolverse y tenían que hacerlo rápidamente. La baja latencia también era una necesidad. Los desarrolladores de Facebook insistieron en construir la solución como un software de código abierto para que otros pudieran beneficiarse de esta idea de SQL distribuido.
En Facebook, PrestoDB alimenta algunas de sus herramientas analíticas, permite realizar consultas interactivas/de BI, así como extracción, transformación y carga por lotes (ETL) de larga duración. También muestra dashboards de alto rendimiento. Además de eso, proporciona una interfaz SQL a otros sistemas NoSQL internos y también es compatible con la infraestructura de pruebas A/B de Facebook. PrestoDB procesa cientos de petabytes de datos todos los días.
Otros casos de uso son las consultas ad-hoc, que permiten consultar datos dondequiera que se almacenen, o consultar sus datos directamente desde un data lake, sin la necesidad de transformarlos. Las respuestas se agregan al consultar diferentes bases de datos, data lakes o lake houses en la nube al mismo tiempo. Finalmente, PrestoDB es compatible con la mayoría de las opciones de fuentes de datos más populares como: AWS S3, Alluxio, Cassandra, Hadoop, Kafka, MongoDB, MySQL y Teradata.
Cualquier empresa que implemente PrestoDB puede realizar (y beneficiarse con) cualquiera de las tareas mencionadas anteriormente, al tener sus diferentes fuentes de datos en múltiples centros de datos. Todo hecho de una manera eficiente, escalable y flexible.
Trino emergió como una solución más amplia
Entre finales de 2018 y principios de 2019, un importante grupo de desarrolladores de PrestoDB abandonó el proyecto y formó Trino (conocido como PrestoSQL hasta 2020). Fue una bifurcación de PrestoDB con la idea de ampliar los casos de uso de la herramienta. A pesar de que PrestoDB y Trino comparten 6 años de historia, desde la división, Trino ha ganado continuamente más popularidad, adopción y desarrolladores que contribuyen al proyecto, en comparación con el PrestoDB original.

Trino fue diseñado para consultar grandes cantidades de datos, distribuyendo las consultas en varias instancias. Sus conectores le permiten interactuar directamente con pilas de computación en la nube. Además, puede manejar varias bases de datos relacionales y se puede actualizar para crear interfaces visuales. De esta manera, Trino ayuda a mejorar el rendimiento y permite a los usuarios completar sus tareas, con ahorro de esfuerzo y recursos.
Según el sitio web del proyecto, “Trino fue diseñado para manejar la analítica y el almacenamiento de datos: análisis de datos, agregación de grandes cantidades de datos y producción de informes. Estas cargas de trabajo (workloads) a menudo se clasifican como procesamiento analítico en línea (Online Analytical Processing, OLAP)“.
PrestoDB se centra en negocios de Big Data similares a Facebook. Por su parte, Trino se ha convertido en mucho más que eso al convertirse en un motor de consultas SQL integral, con mejores capacidades y más adecuado para empresas con diferentes situaciones de datos.
Trino se actualiza varias veces al mes. La implementación de tolerancia a fallos granulares, la migración a Java 17 como base para el código de Trino o las actualizaciones de conectores utilizados para comunicarse con diferentes bases de datos son solo algunos ejemplos del desarrollo constante realizado a este producto por desarrolladores y miembros de la comunidad.
Ejemplos de casos de uso para PrestoDB y Trino
Ya hablamos de la gigantesca base de datos de Facebook que PrestoDB consulta y procesa continuamente. Tanto Presto como Trino son los motores SQL distribuidos más adoptados y se ha demostrado que pueden manejar las cargas de grandes empresas como Netflix, Airbnb, Twitter, Comcast, Uber y muchas más.
Por ejemplo, Robinhood utiliza Trino para el análisis de datos, inteligencia de negocios y para tener visibilidad de su plataforma global para ayudar con los problemas de disponibilidad y rendimiento. La compañía también utiliza varios clústeres Trino conectados a diferentes fuentes de datos, lo que permite a los usuarios empresariales consultarlos cuando quieran.
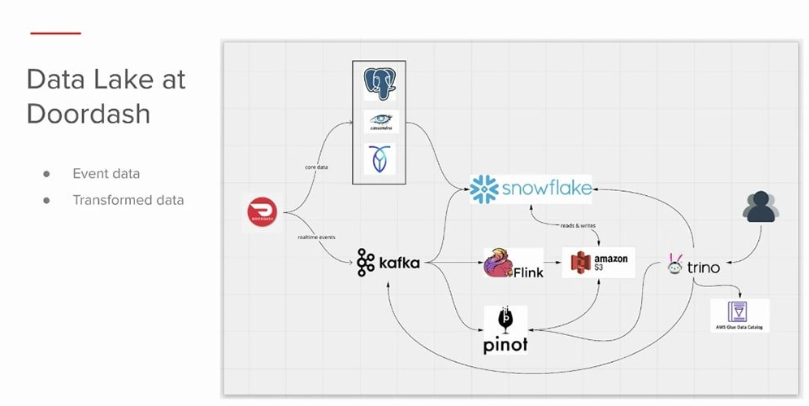
DoorDash utiliza o Trino para habilitar consultas sobre su arquitectura de datos. De forma similar a la estructura de Robinhood, esto permite a los usuarios internos ejecutar análisis de datos sobre procesos y operaciones comerciales.
LinkedIn y Electronic Arts son otras empresas que han adoptado Trino para sus necesidades comerciales.
Resumen
Las arquitecturas de Big Data continúan evolucionando rápidamente. Se necesitan comunidades comprometidas para mantener los software al día y adaptar los productos a los nuevos paradigmas y tendencias para mejorar continuamente. En este contexto, parece que tanto PrestoDB como Trino seguirán liderando el camino como los principales proyectos de código abierto que se centran en desarrollar el poder de los motores SQL distribuidos.