Introducción
Kubeflow es una plataforma creada por Google para facilitar a los desarrolladores la implementación y administración de flujos de trabajo de ML (Machine Learning, aprendizaje automático) en Kubernetes (K8).
En un flujo de trabajo de ML, los ingenieros deben llevar a cabo varias etapas durante la creación de modelos, que incluyen la recopilación y validación de datos, elaboración y entrenamiento del algoritmo, pruebas A/B, elección de infraestructura, implementación, monitoreo y gestión de recursos computacionales.
Además, este proceso se repetirá cientos de veces para optimizar los parámetros según lo requiera el desarrollador. Como resultado, los flujos de trabajo de ML se vuelven cada vez más complejos y requieren mucho tiempo.
Por eso, los sistemas de workflow como Kubeflow son una solución para simplificar y acelerar el desarrollo de nuevos modelos de aprendizaje automático.
Si quieres aprender más sobre Kubeflow, esta publicación te muestra las etapas básicas en el desarrollo de un modelo de aprendizaje automático y cómo Kubeflow junto a sus componentes se integran en este proceso.
Operaciones de aprendizaje automático en Kubernetes
Aprendizaje automático (Machine Learning)
El aprendizaje automático es una rama de la inteligencia artificial que se enfoca en el estudio y la creación de algoritmos avanzados de aprendizaje. Estos algoritmos utilizan estrategias como redes neuronales artificiales, árboles de decisión, análisis de regresión, redes bayesianas, algoritmos genéticos, así como modelos estadísticos y técnicas de inferencia. Aunque ha habido grandes avances en esta área en los últimos años, aún está en constante evolución.
El modelado de ML presenta grandes desafíos, como la necesidad de realizar experimentos precisos y reproducibles, así como tener la libertad para ejecutar flujos de trabajo en diferentes entornos, ya sea en instalaciones locales o servicios en la nube. Para superar estos obstáculos, es necesario avanzar y utilizar nuevas tecnologías y herramientas dedicadas al desarrollo del ML.
Independientemente del número de experimentos, el tipo de modelo y el ambiente en donde se ejecuten, el proceso estándar del desarrollo de modelos de ML puede ser dividido en las siguientes etapas fundamentales:
- Análisis del problema: el ciclo de vida de un modelo de ML comienza con el análisis del problema, que incluye la recopilación, preparación, limpieza y exploración de datos. Con ello, se determina el enfoque óptimo (modelo ML) para resolver el problema.
- Creación del algoritmo y evaluación en laboratorio: esta etapa implica seleccionar y escribir el algoritmo adecuado, así como evaluar el modelo con una cantidad reducida de datos.
- Ajuste de los parámetros del modelo: en esta etapa, los ingenieros evalúan el desempeño del modelo de ML, utilizando métricas como el error relativo, la eficiencia, la exactitud o la precisión. También pueden aplicar un proceso iterativo de optimización para ajustar los coeficientes o los factores de ponderación del modelo.
- Implementación y administración: una vez que el modelo ha sido evaluado y aprobado en función de los requisitos de precisión deseados, el último paso para un científico de datos es implementarlo en un entorno de producción. Esto puede incluir la gestión de grandes cantidades de datos, el monitoreo del desempeño del modelo ML, la realización de ajustes necesarios en los coeficientes del modelo, el reentrenamiento y más.
Sin duda, este proceso no es una regla fija, pero es útil para el propósito de esta publicación. Es importante tener en cuenta que el proceso de creación de modelos de ML puede incluir estos pasos básicos y más, por lo que es posible que los enfoques específicos varíen según el caso. Sin embargo, cualquier algoritmo de ML enfocado a grandes implementaciones requerirá más recursos computacionales, entornos más grandes, como la nube, y herramientas especializadas para su gestión eficaz. Aquí es donde Kubernetes desempeña un papel importante.
Kubernetes
Kubernetes es un software de orquestación de contenedores (containers) de código abierto que facilita la implementación de aplicaciones web y móviles. Además, es una plataforma agnóstica que simplifica la gestión de aplicaciones al abstraer la infraestructura subyacente y proporcionar un conjunto consistente de API. Con Kubernetes, los usuarios pueden definir el estado deseado de sus aplicaciones de forma declarativa, usando archivos de configuración conocidos como manifiestos. Estos manifiestos especifican todos los aspectos del ciclo de vida de la aplicación, incluyendo requisitos de almacenamiento, configuraciones de red, estrategias de equilibrio de carga, comprobaciones de estado y políticas de actualización.
Kubernetes brinda diversas opciones para implementaciones de aprendizaje automático, que incluyen:
- Escalabilidad: Kubernetes ajusta automáticamente la carga de trabajo para adaptarse a la demanda, ya sea manejando conjuntos de datos más grandes o habilitando varias máquinas físicas para una capacitación distribuida.
- Aislamiento: los contenedores brindan un alto nivel de aislamiento, lo cual es esencial cuando se ejecutan tareas con datos confidenciales.
- Monitoreo y observabilidad: los usuarios pueden utilizar funciones de monitoreo para verificar el estado y desempeño de los procesos de aprendizaje automático
- Portabilidad: Kubernetes permite a los usuarios implementar modelos de ML en instalaciones locales, en la nube o en un entorno híbrido, lo que lo hace una opción flexible para diferentes situaciones.
Sin embargo, Kubernetes también presenta desafíos y limitaciones. No cuenta con la capacidad de llevar a cabo todos los pasos necesarios en los flujos de trabajo de ML. Además, la implementación de estos flujos en la plataforma puede ser complicada, ya que suele requerir la combinación de diferentes herramientas y bibliotecas con sus propias dependencias y requisitos específicos. Por esta razón, Google creó el proyecto Kubeflow.
Implementando y gestionando con Kubeflow
Kubeflow es una plataforma de código abierto que facilita la gestión y automatización de flujos de trabajo de aprendizaje automático en Kubernetes. Permite a los ingenieros gestionar y personalizar múltiples modelos, así como definir segmentaciones (pipelines) como procesos de varias etapas, incluyendo la preparación de datos, el entrenamiento y el ajuste.
Kubeflow es ampliamente reconocido por su facilidad de uso, ofreciendo componentes y herramientas intuitivas como Kubeflow Notebooks, Operadores de Entrenamiento (Training Operators), Kubeflow de Segmentación (Kubeflow Pipelines), Servicio de Modelos (Model Serving), Katib, entre otros.
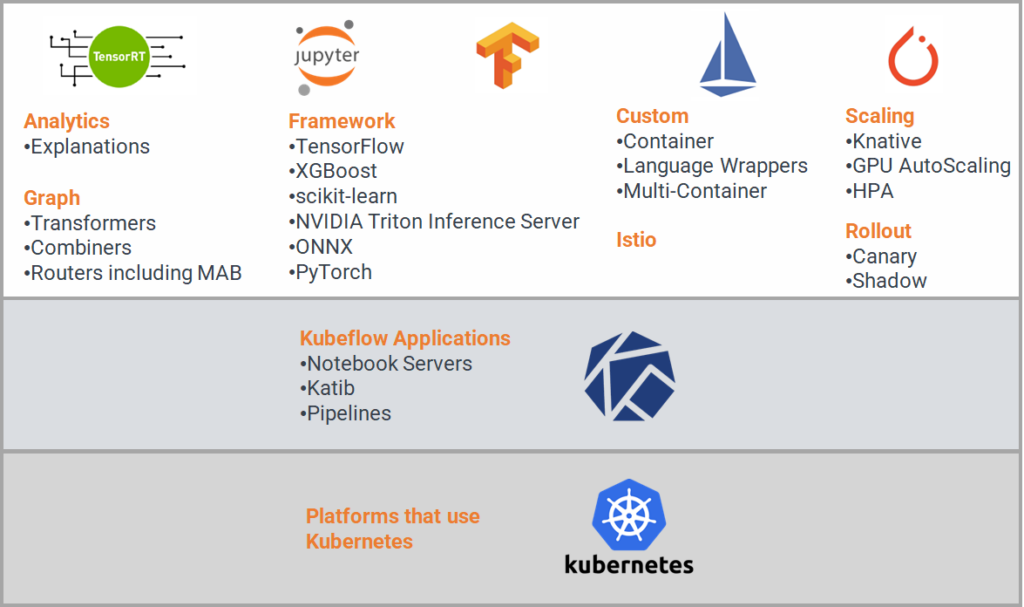
Componentes
Kubeflow Notebooks
Kubeflow facilita la integración de JupyterHub, una herramienta que permite el uso de IDEs que se ejecutan en navegadores web, así como su puesta en marcha como Pods en un clúster de Kubernetes. Además, brinda soporte nativo para Visual Studio Code, JupyterLab y RStudio.
Kubeflow Pipelines
Pipelines es una herramienta para crear y ejecutar flujos de trabajo de aprendizaje automático de principio a fin, a través de una interfaz fácil de usar. Kubeflow Pipelines es un motor de programación que permite a los usuarios enlazar fácilmente diferentes etapas de un pipeline de aprendizaje automático, como procesamiento de datos, entrenamiento y servicio. Además, es compatible con contenedores Docker, lo que facilita el empaquetamiento y la implementación de manera portátil y coherente.
Katib
Katib es una herramienta basada en Kubernetes para AutoML (Automated Machine Learning, aprendizaje automatizado) que brinda funciones como ajuste de hiperparámetros, detención temprana y NAS (Neural Architecture Search, búsqueda de arquitectura neuronal). Compatible con múltiples frameworks, Katib proporciona una amplia variedad de algoritmos AutoML, incluyendo optimización bayesiana, estimadores Tree of Parzen, búsqueda aleatoria, búsqueda de arquitectura diferenciable y más. Actualmente se encuentra en versión beta.
Training Operators
Los Kubeflow Training Operators (Operadores de capacitación de Kubeflow) son un grupo de recursos personalizados de Kubernetes, como TFJob, PaddleJob, PyTorchJob, entre otros, que brindan una forma de automatizar la ejecución y escalado de flujos de trabajo de entrenamiento de aprendizaje automático.
Model Serving
Kubeflow ofrece dos sistemas de servicios de modelos: KFServing y Seldon Core, cada uno equipado con una amplia gama de funciones y opciones para satisfacer las distintas necesidades. Estas características incluyen soporte para diferentes frameworks de aprendizaje automático, gráficos, análisis, escalabilidad, servicios personalizados e integración con Istio para la gestión de tráfico, telemetría y seguridad.
En resumen
Kubeflow es una plataforma de código abierto que facilita la implementación y la gestión de flujos de trabajo de aprendizaje automático en el entorno de Kubernetes. Inicialmente diseñada para ejecutar trabajos de TensorFlow, Kubeflow ha evolucionado para integrar compatibilidad con otros frameworks y herramientas de código abierto, como PyTorch, Chainer, MXNet, XGBoost, Istio, Nuclio, entre otros. Además, hoy en día empresas tecnológicas de gran envergadura como IBM, Red Hat y Cisco utilizan y contribuyen al desarrollo de Kubeflow.