Al construir un stack de Inteligencia Artificial (IA) se debe dar prioridad a las tareas que realizan la ingesta de datos, el procesamiento paralelo, el procesamiento de stream, la computación distribuida (workloads, o cargas de trabajo) y el almacenamiento. En Machine Learning (ML), el procesamiento paralelo es diferente al procesamiento de stream. Kafka y Spark Streaming (una extensión de Spark) son procesadores de stream que ingieren datos de logs de servidores, dispositivos IoT, sensores, entre otros. Luego, los transforman en un formato más útil que se puede enviar a otro sistema.
Frameworks de IA, como TensorFlow y Pytorch, están preparados para realizar procesamiento paralelo, al dividir las tareas en partes y luego distribuir las cargas de trabajo entre múltiples GPU y nodos.
Uso de TensorFlow con Spark
Fundada en 2013, Databricks es la empresa detrás de Apache Spark. Tim Hunter, Ph.D. e ingeniero de software de Databricks, escribió un artículo en el que describe los beneficios de usar Spark con TensorFlow. Apache Spark (no Spark Streaming) se puede utilizar para escalar las cargas de trabajo de TensorFlow durante el entrenamiento de modelos de ML y la posterior fase de inferencia.
Para el entrenamiento de modelos, Spark es útil para escalar el ajuste de hiperparámetros. El ajuste de hiperparámetros se encuentra bajo el término general de “Optimización de Modelo”. Google describe el mismo proceso como “Optimización de Hiperparámetros”. Por lo tanto, el proceso de ajustar los parámetros correctos en cada modelo es de vital importancia, ya que afecta el rendimiento y la precisión de un modelo.
Jesus Rodriguez, CTO de IntoTheBlock escribe que “ramas enteras del Machine Learning (o aprendizaje automático) y las teorías de aprendizaje profundo (deep learning) se han dedicado a la optimización de modelos” y “la optimización a menudo implica elementos de ajuste que se encuentran fuera del modelo, pero que pueden influir en gran medida en su comportamiento”. De tal manera, los hiperparámetros son los elementos ocultos en los modelos de aprendizaje profundo que se pueden ajustar para controlar el comportamiento. TensorFlow y otros modelos incluyen hiperparámetros básicos como la tasa de aprendizaje. Sin embargo, el proceso de encontrar los mejores hiperparámetros para cierto modelo requiere experimentación y esfuerzo manual.
Ejemplos de hiperparámetros
- IntoTheBlock: 1) Tasa de aprendizaje; 2) Número de unidades ocultas; 3) Ancho del núcleo de convolución.
- Google: 1) Tasa de aprendizaje; 2) Tasa de abandono en la capa de abandono; 3) Número de unidades en la primera capa densa; 4) Optimizador.
- Hvass Labs: 1) Tasa de aprendizaje; 2) Número de capas densas; 3) Número de nodos densos; 4) Función de activación.
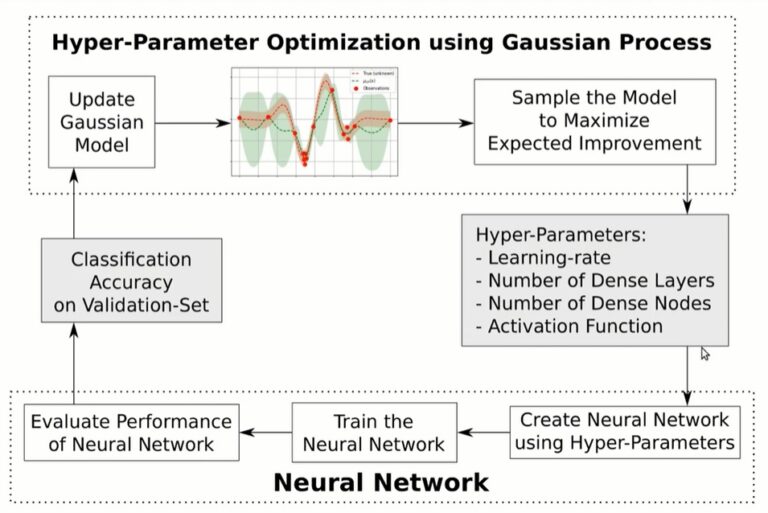
En un ejemplo, Hvaas Labs describe los pasos de optimización de hiperparámetros para un modelo particular usando el “Proceso Gaussiano” y TensorFlow.
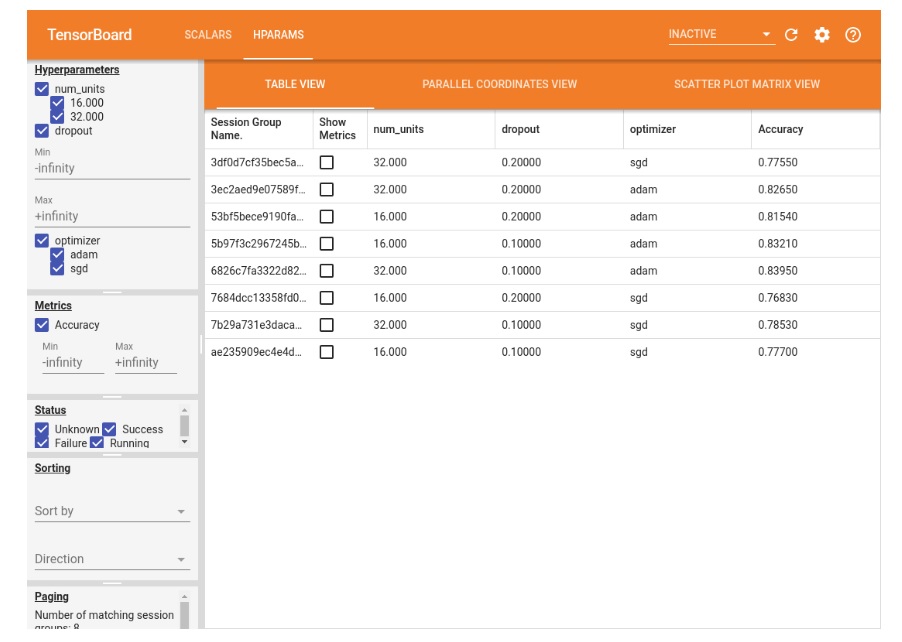
En otro ejemplo, Google muestra tres hiperparámetros en TensorBoard para un modelo en particular que incluyen 1) número de unidades; 2) abandono, y 3) optimizador.
En el artículo de Databricks, el autor describe el proceso de transformación de una imagen, como el conjunto de datos NIST “clásico”, en dígitos para que un modelo de Machine Learning pueda leerlo. Al usar TensorFlow, la herramienta es capaz de leer la imagen, luego realizar el cálculo matemático para convertir los píxeles de la imagen en “señales” que son leídas por el algoritmo. Aunque TensorFlow crea algoritmos de entrenamiento, la parte más difícil es seleccionar los hiperparámetros adecuados. Si se seleccionan los parámetros adecuados, el modelo funciona bien. En caso contrario, el rendimiento del modelo decae.
Curiosamente, el autor explica que “TensorFlow en sí no está distribuido. El proceso de ajuste de hiperparámetros es vergonzosamente paralelo y se puede distribuir utilizando Spark”. Sin embargo, Gonzalo Meza, un ingeniero de Google, afirma que TensorFlow “realmente no se preocupa por la infraestructura subyacente” porque hay una función llamada tf.distribute.strategy que permite que la “API de TensorFlow distribuya el entrenamiento a través de múltiples GPU, múltiples máquinas o TPU”. En otras palabras, TensorFlow es “vergonzosamente paralelo” desde su instalación.
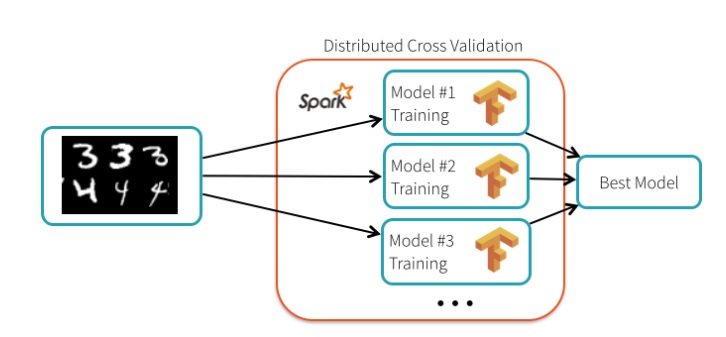
En una prueba de ajuste de hiperparámetros, el equipo de Databricks configuró un clúster de 13 nodos para realizar la prueba. Lograron una tasa de precisión de 99.47%, que fue 34% mejor que ejecutar el proceso con la configuración predeterminada para TensorFlow. Cada nodo ejecutó un modelo diferente, el entrenamiento fue realizado en paralelo satisfactoriamente.
Escalar con TensorFlow y PyTorch
TensorFlow y PyTorch tienen soporte nativo para Machine Learning distribuido. TensorFlow tiene una API llamada tf.distribute.strategy que permite que las cargas de trabajo de entrenamiento se distribuyan entre nodos, TPU y GPU. Los beneficios de tf.distribute.strategy incluyen:
- Escala de nodo único a múltiples nodos y GPU/TPU.
- Admite múltiples grupos de usuarios.
- Mejora el rendimiento.
- Se puede utilizar con Keras.
- Es compatible con entrenamiento síncrono y asíncrono:
- Síncrono: “todos los trabajadores se capacitan en diferentes segmentos de datos de entrada en sincronización y agregando gradientes en cada paso”.
- Asíncrono: “todos los trabajadores están capacitándose de forma independiente sobre los datos de entrada y actualizando las variables de forma asíncrona”.
- Es compatible con seis estrategias: 1) MirroredStrategy 2) TPUStrategy 3) MultiWorkerMirroredStrategy 4) CentralStorageStrategy 5) ParameterServerStrategy y 6) OneDeviceStrategy.
PyTorch tiene una función llamada DataParallel. Se trata de una “técnica de entrenamiento distribuido” que permite replicar el entrenamiento a través de diferentes GPU en el mismo nodo para acelerar el entrenamiento. Otra característica de PyTorch es Model Parallel que “divide un solo modelo en diferentes GPU, en lugar de replicar todo el modelo en cada GPU”. Por ejemplo: si un modelo contiene 10 capas (entrada + salida + 8 ocultas), cada capa se puede colocar en una GPU en diferentes dispositivos. Si se utiliza una máquina con 2 GPU, entonces se pueden procesar 5 capas en cada GPU.
Procesamiento de Stream
Ahora podemos discutir otro tipo de procesamiento llamado procesamiento de stream. El procesamiento de streams implica la ingesta y el procesamiento de secuencias de datos en vivo. Los flujos de datos pueden ser cualquier cosa, desde weblogs hasta datos de dispositivos IoT, datos de sensores, entre otros. Dos procesadores de stream populares son Kafka y Apache Spark Streaming. Ambas herramientas se utilizarán en nuestra arquitectura de referencia. Spark Streaming y Kafka son bastante conocidos y utilizados por miles de empresas en todo el mundo. Spark Streaming es una extensión de Spark y proporciona capacidades de proceso de stream a Spark, ya que de forma nativa no sería posible.
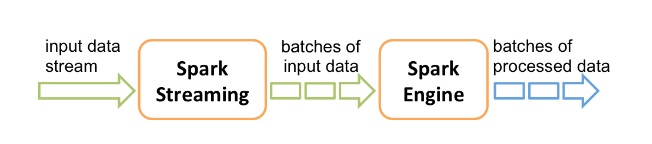
Como se ilustra en el siguiente diagrama, Spark Streaming ingiere flujos de datos en tiempo real de una fuente de datos. Luego, divide esos flujos en lotes llamados RDD. La recopilación de lotes de RDD es el DStream que representa el “flujo continuo de datos”. A partir de entonces, los RDD alimentan al Spark. A partir de ahí, los datos pueden sufrir una transformación adicional o ser alimentados a otro sistema como una base de datos o un modelo de ML.
Spark Streaming
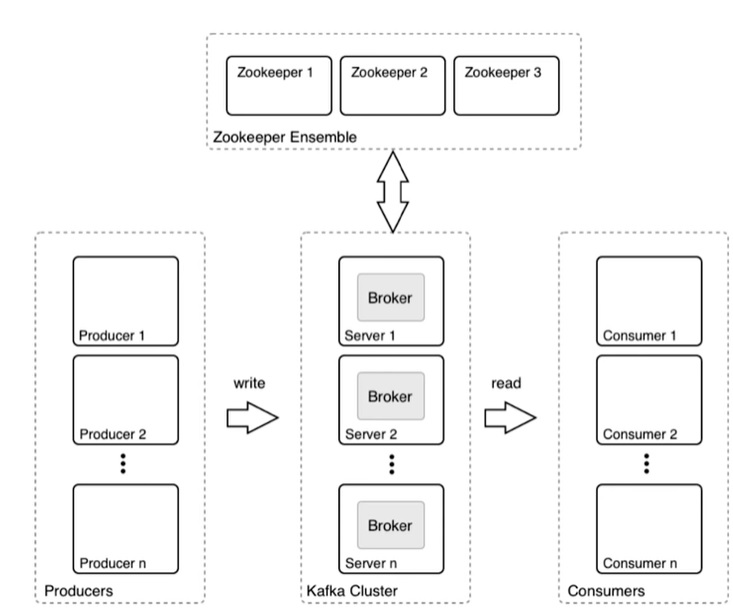
Kafka es el sistema más robusto de los dos. En el siguiente gráfico, se ilustran las partes de Kafka. El productor es cualquier aplicación o sistema que genera datos brutos como un dispositivo IoT, servidor web, base de datos, enrutador, etc. El clúster Kafka ingiere los datos sin procesar del productor, los pone en cola si el volumen de datos es alto y luego los reenvía al consumidor que se suscribe al tópico. El tópico es el nombre del feed o categoría de datos.
En resumen, hay stacks disponibles para ayudar con la ingesta de datos, el procesamiento paralelo, el procesamiento de stream, la computación distribuida y el almacenamiento.