En el mundo del Big Data y del Machine Learning (ML), algunas herramientas se pueden aplicar para cualquier caso de uso. Cuando se trata de big data, las más populares son Hadoop, MapReduce y Spark; aunque también son adecuadas para el aprendizaje automático, como es conocido el Machine Learning en español. Hace unos años, Hadoop era la tecnología de facto de código abierto para big data. Sin embargo, el interés ha disminuido a medida que algunos proveedores de nube de datos, como Snowflake, facilitan el trabajo con datos de manera rentable.
Hadoop es un pilar importante para algunas organizaciones porque es altamente escalable y redundante. Por lo tanto, el procesamiento de grandes volúmenes de datos se puede distribuir entre grupos de servidores de cualquier tamaño.
Hadoop es un framework con múltiples funcionalidades, pero en su núcleo es un sistema de archivos distribuidos. MapReduce funciona junto con Hadoop y proporciona capacidades de procesamiento al trabajar con datos estructurados y no estructurados. No obstante, MapReduce tiene muchas limitaciones, razón por la que surgió Spark.
En 2015, el científico informático Matel Zaharia creó Spark mientras estaba en la UC Berkeley. En general, Spark es un producto mejor que MapReduce por las siguientes razones: 1) se ejecuta en memoria (in-memory) por lo que es más rápido que MapReduce, que trabaja en disco duro; 2) Spark se ejecuta en muchas plataformas diferentes, incluida Kubernetes; 3) Spark funciona con procesamiento por lotes (batch) y datos en tiempo real (stream), mientras que MapReduce solo funciona con procesamiento por lotes y; 4) el ecosistema Spark está creciendo y bibliotecas como MLib se han desarrollado específicamente para Spark. Spark MLib es una popular biblioteca de Machine Learning compatible con cómputo tipo NumPy y viene con diferentes algoritmos. Lo más importante es que Spark tiene la capacidad de distribuir las cargas de trabajo de ML entre diferentes recursos.
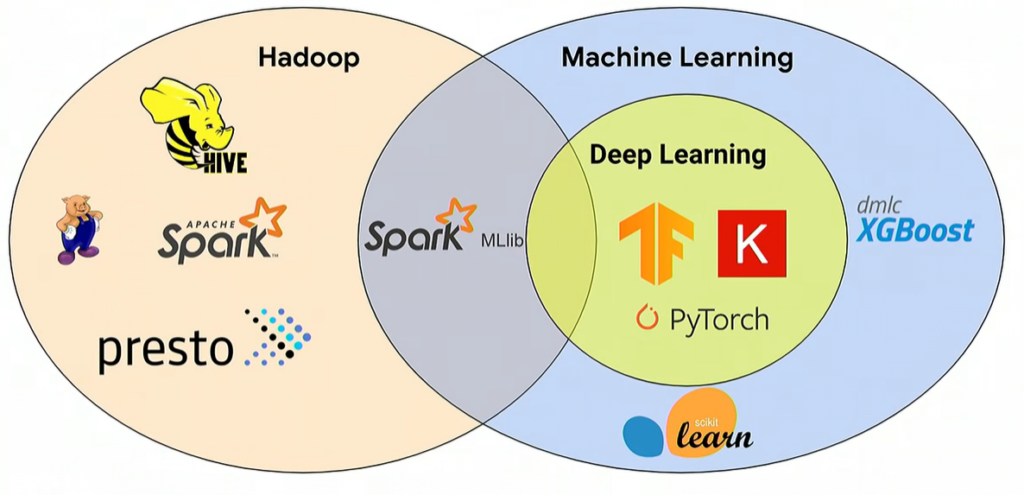
Apache Spark y TensorFlow
Las tres fases principales del Machine Learning son la preparación de los datos, el entrenamiento y la inferencia. El entrenamiento requiere más recursos informáticos que la inferencia porque los datos fluyen varias veces en ambas direcciones entre las capas, hasta que la precisión del modelo alcanza un objetivo establecido. El tiempo de entrenamiento puede durar desde horas hasta semanas, dependiendo del tamaño del conjunto de datos y la complejidad del modelo (número de capas y neuronas). Por lo tanto, reducir el tiempo de entrenamiento es clave para que un modelo pase a producción más rápido. En el siguiente gráfico, hay cuatro capas y diez neuronas en este modelo de aprendizaje profundo (deep learning). En términos de complejidad del modelo, se encuentra en algún lugar entre simple y complejo.

Un ejemplo de Google
El ingeniero de Machine Learning de Google Gonzalo Gasca Meza describe un método para reducir el tiempo de entrenamiento al utilizar el aprendizaje automático distribuído. Cuando se trata de experimentación con modelos, una práctica recomendada es ejecutar tareas en paralelo, como la búsqueda de hiperparámetros (ajustes) en diferentes nodos. Esto es especialmente cierto cuando se trabaja con grandes conjuntos de datos y el volumen de datos es mayor que la capacidad de un solo nodo. TensorFlow permite dividir y distribuir las tareas en diferentes máquinas para su procesamiento con el fin de acelerar el tiempo de entrenamiento.
Cuando se avanza de la experimentación a la fase de producción, entran en juego los pipelines de ML. Gonzalo divide el proceso de ML en tres fases: preparación de los datos, entrenamiento y servicio.
- Preparación de los datos: implica ingeniería de funciones y ETL. El trabajo principal aquí es recopilar datos y crear funcionalidades que representen los datos en una tabla. No se necesita un GPU para esta fase, por lo que un clúster de CPU debería funcionar. Apache Spark participa en esta fase.
- Entrenamiento: después de que se preparan los datos, se lleva a cabo el entrenamiento. Los clústeres de GPU deben usarse en esta fase. Además, se necesita un administrador de recursos, para asignar las cargas de trabajo a los GPU.
- Servicio: al completar el entrenamiento, el modelo se gradúa en producción. Las cargas de trabajo se pueden distribuir entre CPU y GPU; además, pueden ejecutarse en Kubernetes o Docker. Se puede agregar más GPU para mejorar el rendimiento.
Fuente: Machine Learning con TensorFlow y Pytorch
Otras herramientas
Existen otras herramientas que tienen un papel importante en el contexto de Machine Learning, como el administrador de recursos y el programador de trabajos. YARN, creado para Hadoop, es un administrador de recursos y planificador de trabajos que asigna recursos en un clúster.
En las últimas versiones de YARN y HADOOP (3.1x), hay soporte de primera clase para GPU. Por lo tanto, YARN es capaz de programar recursos para ejecutarse en GPU, independientemente del volumen. Otra herramienta es Kubeflow, que simplifica la implementación de flujos de trabajo de Machine Learning en Kubernetes. Sin embargo, no es compatible con Hadoop. Aquí es donde TFS entra en juego. TensorFlowOnSpark (TFS) admite modelos de aprendizaje profundo que se ejecutan en Apache Spark y Hadoop. Yahoo desarrolló este producto para escalar modelos de aprendizaje profundo para que funcionen eficientemente en clústeres de GPU y CPU.
TonY
TonY es un framework de deep learning desarrollado por LinkedIn. “Ejecuta de forma nativa trabajos de aprendizaje profundo en Apache Hadoop”. Como se ilustra en el gráfico anterior, TonY es el único producto que se ejecuta en Hadoop, admite GPU y tiene soporte nativo de YARN. Además, soporta los siguientes frameworks: PyTorch, TensorFlow, MXNet, y Horovod. Con las últimas versiones de YARN y Hadoop, las cargas de trabajo se pueden distribuir entre GPU y servidores.En resumen, Hadoop, YARN y Spark se pueden utilizar en modelos de aprendizaje automático o Machine Learning.