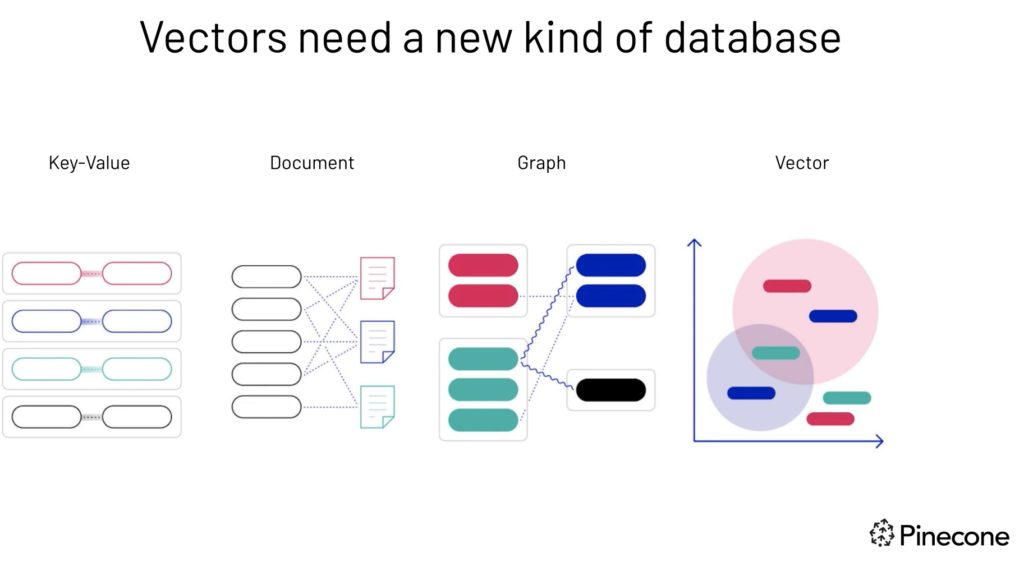
Las bases de datos vectoriales se han convertido en un elemento cada vez más importante para Machine Learning (ML), o aprendizaje automático. Las bases de datos tradicionales no son adecuadas porque se crearon hace décadas para resolver diferente tipos de problemas. Esto aplica para bases de datos SLQ y NoSQL.
Las bases de datos SQL (SQL DB) funcionan con datos estructurados y utilizan funcionalidades como claves primarias, tablas (filas y columnas) y atributos para describir, almacenar y organizar los datos. Una de las debilidades de las SQL DB es su incapacidad para escalar horizontalmente para soportar cargas de trabajo crecientes.
En el otro extremo están las bases de datos NoSQL. Trabajan con datos semiestructurados y no estructurados y existen diferentes tipos como bases de datos documentales, de clave-valor, datos en grafo y base de datos orientada a columnas. Uno de los principales beneficios de las NoSQL DB es su capacidad para escalar horizontalmente, soportando cualquier volumen de carga de trabajo.
Aunque las bases de datos SQL y NoSQL pueden funcionar para algunos casos de uso de ML, las bases de datos vectoriales son más adecuadas para casos de uso que involucran texto, búsqueda, recomendación, audio y NLP (Procesamiento de Lenguaje Natural).
Pinecone: The Rise of Vector Data.
¿Qué es una base de datos vectorial?
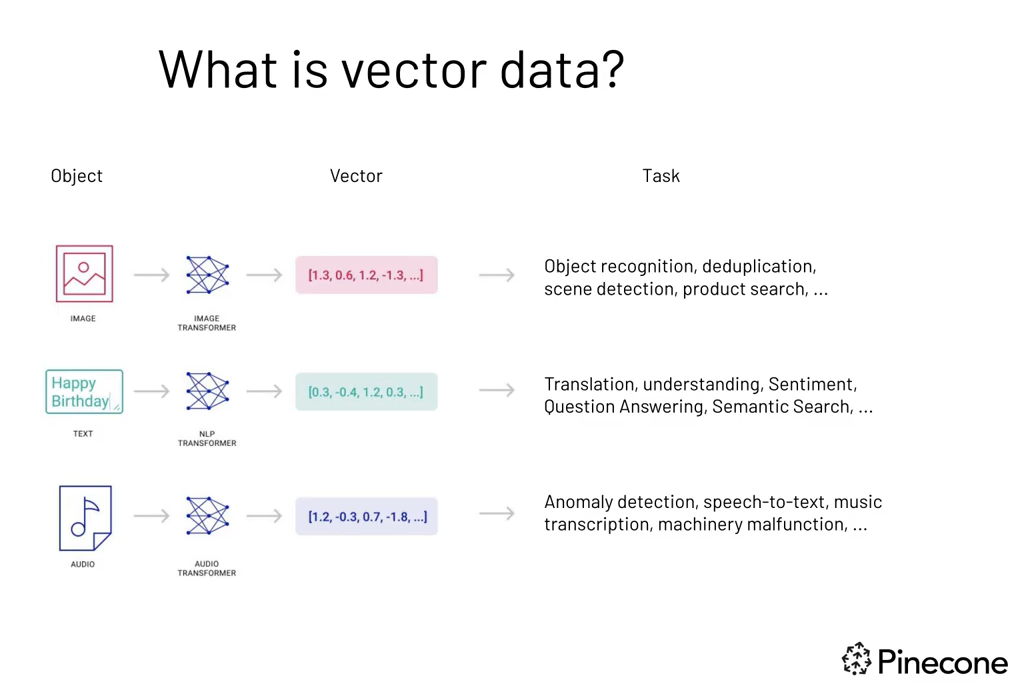
Una base de datos vectorial almacena datos tales como texto, imagen y audio en forma de vectores. Un vector es una lista de números representados como una secuencia o como un único valor en una fila y un único valor en la sección de columna. Lo vemos ilustrado a continuación.
- Escalar: tiene magnitud como distancia, velocidad, tiempo, temperatura y área.
- Vector: tiene magnitud y dirección tales como velocidad, momento y aceleración.
- Matriz: tabla de números que representan filas y columnas

Fuente: mathisfun.com
Las bases de datos vectoriales difieren de las bases de datos tradicionales porque los datos no se almacenan en tablas o como documentos, sino como valores numéricos a lo largo de un eje “X” y otro eje “Y”, representados como una secuencia de números como se muestra a continuación.
Pinecone: The Rise of Vector Data.
Cada tipo de datos, ya sea una imagen, audio o texto, debe transformarse a secuencias de números. Por ejemplo, en NLP, un transformador como GPT-3 se utiliza para transformar datos de un formato a otro. Desglosándolo aún más, hay un proceso llamado incrustación de palabras que asigna un valor numérico único a una palabra.
Bases de datos vectoriales
El sector de bases de datos vectoriales está en crecimiento. Actualmente, hay algunos productos de código abierto en el mercado, y también hay otros productos comerciales disponibles como Pinecone. Algunos se han desarrollado desde cero para respaldar los requisitos de datos únicos de ML.
Milvus
Milvus es una de las bases de datos vectoriales de código abierto más populares que puede administrar billones de conjuntos de datos vectoriales. Es ampliamente utilizado en casos como el descubrimiento de nuevos medicamentos, la conducción autónoma, los chatbots, la visión por computadora y los motores de recomendaciones.
Características
- Búsqueda de milisegundos en trillones de conjuntos de datos vectoriales.
- Gestión simplificada de datos no estructurados.
- Confiable.
- La escalabilidad y elasticidad a nivel de componente hacen que la programación de recursos sea más eficiente.
- Facilita la búsqueda híbrida sobre tipos de datos como enteros, booleanos, números de coma flotante y más.
- La estructura lambda unificada hace que el procesamiento por lotes sea atemporal y eficiente.
- Excelente soporte de la comunidad, con más de 1.000 usuarios empresariales, más de 8.000 estrellas en GitHub.
Weaviate
Weaviate es un motor de búsqueda vectorial de baja latencia basado en Go y una base de datos vectorial. Utiliza ML para vectorizar, almacenar datos y responder consultas de lenguaje natural. La plataforma proporciona soporte excepcional para diferentes tipos de medios, como imágenes y texto. También facilita la búsqueda semántica, modelos personalizables, extracción de preguntas y respuestas, clasificación y más.
Dado que almacena tanto objetos como vectores, los usuarios pueden combinar la búsqueda vectorial y el filtrado estructurado con la tolerancia de una base de datos nativa de la nube. Es accesible a través de REST, GraphQL y otros clientes de lenguaje.
Características
- Consultas rápidas. Puede realizar una búsqueda de diez “vecinos más cercanos” (ten nearest neighbor search) entre millones de objetos en menos de 100 ms.
- Admite cualquier tipo de datos.
- Combina búsqueda escalar y vectorial.
- Puede procesar datos en tiempo real, y las escrituras se realizan en un registro de escritura anticipada (Write-Ahead-Log, WAL) para escrituras inmediatamente persistentes.
- Weaviate puede ser escalado según las necesidades del proyecto: grandes conjuntos de datos, ingestión máxima, alta disponibilidad.
- Rentable. Los grandes conjuntos de datos no ocupan memoria y la memoria se puede utilizar para aumentar la velocidad de las consultas.
- Hace conexiones arbitrarias similares a grafos entre objetos.
Vespa
Vespa es un motor de búsqueda de texto repleto de funciones que permite la consulta de información tradicional y las técnicas modernas basadas en incrustaciones. Además, se utiliza ampliamente para la recomendación y la personalización, responder preguntas y la navegación semiestructurada.
Características
- Búsqueda rápida de vecinos más cercanos (ANN) en espacios vectoriales.
- Relación por metadatos estructurados.
- Combinación de operadores coincidentes en la misma consulta por AND y OR.
- Facilita la clasificación en 2 fases.
- Clasificación por expresiones matemáticas arbitrarias sobre características tensoriales y escalares.
- Relaciones globales de agrupación, agregación y deduplicación.
Vald
Vald es un motor de búsqueda vectorial rápido ANN distribuido de código abierto y totalmente escalable. Se ejecuta en la arquitectura nativa de la nube y utiliza el algoritmo ANN más rápido, llamado NGT, para buscar vecinos. El motor de búsqueda facilita la indexación vectorial automática y la copia de seguridad del índice, así como el escalado horizontal para buscar entre miles de millones de datos vectoriales. Puede ser personalizado en función de necesidades particulares.
Características
- Indexación automática asíncrona.
- Filtrado de entrada/salida personalizable.
- Motor de búsqueda vectorial basado en la nube.
- Copia de seguridad de indexación automática.
- Indexación distribuida.
- Replicación del índice.
- Fácil de usar.
- Altamente personalizable.
- Compatible con varios lenguajes.
Pinecone
Pinecone es una base de datos de vectores comercial y totalmente administrada diseñada para facilitar la adición de búsqueda de vectores a las aplicaciones en producción. El producto combina bibliotecas de búsqueda vectorial, así como funciones como filtrado e infraestructura distribuida. Por encima de todo, proporciona una búsqueda de alto rendimiento independientemente de la escala.
Características
- Búsqueda de miles de millones de vectores en decenas de milisegundos.
- Opera en entornos GCP o AWS, seguros en múltiples regiones.
- Facilita la búsqueda semántica y la búsqueda de datos no estructurados.
- Se utiliza para la duplicación y coincidencia de registros, recomendaciones y clasificación, detección y clasificación.
Kinetica
Kinetica es una base de datos de vectores comercial que admite de forma nativa la vectorización en GPU y CPU. Es básicamente una plataforma de memoria con almacenamiento por niveles que utiliza la vectorización para paralelizar tareas en niveles de instrucción. Viene con un conjunto de herramientas analíticas integradas que ayudan a ofrecer análisis en tiempo real y transmisión de alta velocidad.
Características
- Procesamiento secuencial.
- Procesamiento paralelo a nivel de tarea.
- Procesamiento paralelo a nivel de datos (vectorización).
- Aprendizaje automático.
- Análisis de gráficos.
- Análisis de IoT.
- Análisis en tiempo real.
- Optimización de la cadena de suministros.